IHFX分享:从图灵测试到ChatGPT——人机对话的里程碑及启示
图灵奖得主、深度学习之父辛顿(Geo? Hinton)说:“深度学习的下一个大的进展应当是让神经 网络真正理解文档的内容。”机器学习著名学者乔丹( Michael Jordan)说:“如果给我 10 亿美元,我会 用这 10 亿美元建造一个 NASA 级别的自然语言研究项目。”图灵奖得主杨乐昆(Yann LeCun)说:“深 度学习的下一个前沿课题是自然语言理解。”微软全球执行副总裁沈向洋说:“下一个十年,懂语言者 得天下。”微软创始人比尔 ·盖茨( Bill Gates ) 2019 年 6 月在华盛顿经济俱乐部午餐会接受采访时说: “我将创建一家人工智能公司,目标是让计算机学会阅读,能够吸收和理解全世界所有的书面知识。”

这些人工智能学界的著名人士不约而同地把他们的慧眼都聚焦到自然语言处理问题,都主张让计 算机理解自然语言,可见,自然语言处理是人工智能的一个非常重要的问题。本文描述自然语言处理 从图灵测试到 ChatGPT 的发展历程中的几个关键事件,借此探讨技术、数据和范式发展的趋势。
一、人工智能与语言的最初碰撞:图灵测试
早在 1936 年,英国数学家图灵( Alan M. Turing)在研究可判定问题时就已提出,可以让计算机 理解自然语言,从而证明计算机能够具备人的思维能力( Turing 1936 )。
1946 年,第一台电子计算机 ENIAC 问世。 1950 年,图灵在《计算机器与智能》一文中提出,检验计 算机是否具备智能,最好的办法是让它说英语并理解英语。为此, 图灵亲自设计了“图灵测试”(Turing test)。图灵测试采用问与答的模式进行。让密闭在小屋中的一个测试者通过控制打字机与小屋外的两个测 试对象通话,其中一个测试对象是没有生命的计算机,另一个是活生生的人。小屋内的测试者不断提出各 种问题,通过回答辨别小屋外的究竟是计算机还是人(Turing 1950)。如果计算机能够非常好地模仿人回答问题,以至于测试者在充分的交流中误认为它是人而不是机器,就可以称这台计算机能够思维。

图灵借由行为主义的观点来判断智能的存在,这一关键行为就是人类语言(中的对话)。这可视 为语言与人工智能的最初碰撞。
二、早期受限对话的代表: ELIZA
美国科学家魏岑鲍姆(Joseph Weizenbaum) 1966 年设计了一个叫作 ELIZA 的程序,这个程序模仿 一个同名机器人医生与用户的对话来做图灵测试( Weizenbaum 1966 )。ELIZA 系统能与用户进行有一 定限制的对话。在对话中, ELIZA 模仿用户说话的表达方式,使用模式匹配的方法来处理输入,并且 把这种处理过的输入转换成适当的输出来回答用户的问题。这是一个非常简单的模式匹配系统。
尽管在 ELIZA 系统中,计算机只是使用模式匹配的方法模仿人的语言行为,实际上并没有理解语 言; 然而, 由于魏岑鲍姆设计得很巧妙, 以至于很多与 ELIZA 对话的人都相信, ELIZA 确实理解了他 们所说的话以及他们提出的问题。
在这一阶段,受限于数据规模、计算能力,基于规则的系统是主流。对 ELIZA 而言,写好的对话 模板充当了语言系统规则的作用。ELIZA 实际上是在遵循一系列规则的引导,从对话开头走向结尾。这 些精细规则的制定由语言学家和计算机专家合作完成。扩充规则的成本巨大, 且规则规模达到一定程度 后,对其进行管理十分困难。显然这样的系统泛化能力很弱,不能应对超出规则之外的语言现象。、
三、对话能力是否代表智能的争议:“中文屋子”问题
美国哲学家塞尔( John. R. Searle ) 1980 年在《心智,大脑和程序》一文中,提出了所谓“中文屋 子”( Chinese room )的问题,对图灵测试进行质疑( Searle 1980)。塞尔提出,假设有一个只会英文 的人被关在一间屋子里,要求他回答从小窗递进来的纸条上用中文书写的问题。他面前有一组英文指 令,说明中文符号和英文符号之间的对应关系和操作关系。他首先要根据指令中的规则来操作问题中 出现的中文符号,估测出问题的含义,然后再根据规则把答案用中文逐一写出来。虽然他完全不会中 文,但是,通过这种操作,他可以让屋子外的人以为他会说流利的中文。塞尔以此说明,计算机只是 善于根据规则做机械的操作而已(这与当时基于规则的语言处理系统十分相似),这并不能证明计算 机具备智能。塞尔的批评是对图灵测试的一个挑战。
塞尔提出“中文屋子”问题以来,哲学家和人工智能研究者关于图灵测试究竟是否适合用来测试 智能的争论持续了很多年,至今还没有平息。
如果我们使用人机对话技术,就能够在很多应用方面给众多用户提供更加自然的交互界面。这就产 生了一个被称为“智能会话代理”的研究焦点。所谓智能会话代理,就是能够通过会话与人们进行交际 的计算机人造实体,在智能会话代理中,尽管计算机也只是模仿人们的自然语言,但是,人们往往会误 以为计算机理解了自然语言(冯志伟 2014)。这样的代理甚至可以在一些受限领域提供良好的服务(如 医疗问答、酒店预订、交通查询等),在领域落地的实践中,人们不再关心语言能力与心智的哲学问题。
四、数据驱动范式的成功:沃森
进入 21 世纪,人机对话系统在算力增长和数据量扩张的刺激下,取得了飞跃式的进步。计算机“沃森”(Watson)赢得电视问答竞赛的人机大战,则向世界直观地展示了人机对话系统取得的巨大成就。
2011 年 2 月 14 ~ 16 日,美国著名的智力竞答电视节目《危险边缘!》( Jeopardy! )举办了一场人 机竞答比赛。参加比赛的计算机是美国国际商用机器公司(IBM)研制的超级计算机“沃森”,人类 选手则是曾经多次赢得《危险边缘! 》竞答冠军的布拉德 ·布特和肯 ·詹宁斯。首日比赛中,沃森与 布特打成了平手,领先于詹宁斯; 次日比赛中,沃森答对了 30 道测试题中的 24 道,詹宁斯和布特分 别只答对 3 道和 2道; 2 月 16 日竞赛揭晓,沃森以绝对优势战胜了人类高手,获得冠军,赢得 100 万 美元奖金(开发者捐给了慈善机构)。这是计算机自动问答系统研究引起世界瞩目的重要成就。
沃森是 20 多名 IBM 研究人员 4 年心血的结晶。它由 90 台 IBM 服务器组成,拥有 15TB 的存储容 量、 2880 个处理器线程,每秒可进行 80 万亿次运算。它存储了包括辞书、百科全书和电影剧本在内 的数百万种资料。在 IBM 强大的数据检索、并行计算基础上,沃森充分融合了基于统计自然语言处理 方法的自然语言的结构分析、自然语言的语义技术,然后用自然语言做出回答( Ferrucci et al. 2013 )。 研究人员突破性地给予了沃森用自然语言精确回答问题的能力,推动了人工智能的发展。
20 世纪 90 年代以来,随着互联网兴起和硬件快速发展,自然语言处理所需的数据规模和大规模计算 所需的硬件基础得到了显著提升。自然语言处理的研究和开发由依赖专家知识的规则系统, 向依赖大数 据和统计分析的统计路线转换。对话代理在这一阶段逐步发展成熟,开始更深地进入更多日常生活领域。
五、深度神经网络的前沿技术:预训练模型
2012 年以来,自然语言处理开始从统计学习向端到端的神经网络深度学习方法转型,大大地提高 了处理系统的性能,使得自然语言处理进入了崭新的阶段,基本上形成了一套完备的技术体系,标志 着自然语言处理进入了大规模工业化实施的时代(冯志伟 2019 )。
在深度学习和神经网络的研究中,语言数据资源不足是一个严重的问题。例如,商用神经机器翻 译系统需要包含数千万个句子甚至数亿个句子的大数据作为训练语料。如果语言数据不足,自然语言 处理系统的质量就难以保证。为了解决这一问题, 学者们开始探讨在小规模语言数据中研制自然语言 处理系统的可行性问题,提出了“预训练语言模型”(冯志伟,李颖 2021 )。如图 1 所示。
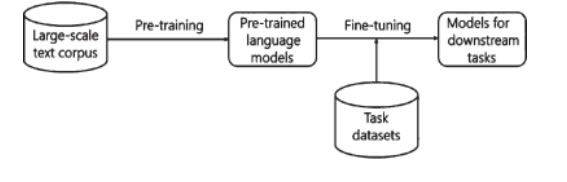
图 1 预训练语言模型
预训练语言模型使用大规模文本语料库数据(Large-scale text corpus)进行预训练(Pre-training), 建立预训练语言模型( Pre-trained language models),然后使用面向特定任务的小规模语言数据集( Task datasets),根据迁移学习的原理进行微调(Fine-tuning),形成下游任务的模型( Models for downstream tasks)。这样的预训练语言模型使得研究者能够专注于特定的任务,而适用于各种任务的通用的预训 练语言模型可以降低自然语言处理系统的研制难度,从而加快了自然语言处理系统研究创新的步伐。
使用这样的“预训练范式”,研究人员设计出各种预训练模型,可以把通过预训练从大规模文本数据中学习到的语言知识,迁移到下游的自然语言处理和生成任务模型的学习中。预训练模型在几乎 所有自然语言处理的下游任务上,都表现出了优异的性能, 进一步验证了预训练模型确实是一个功能
强大的大语言模型,在自然语言处理的研究和应用领域产生了广泛的影响。
由 OpenAI 公 司 开 发 的 基 于 转 换 器(Transformer) 的 生 成 式 预 训 练 模 型( Generative Pre-trained Transformer, GPT)已经成为当前自然语言处理研究的核心技术。GPT 利用转换器模型的编码器和解 码器,从语言大数据中获取了丰富的语言知识,在自然语言生成任务上达到了相当高的水平。这样一 来,生成式预训练模型 GPT 便成为深度学习神经网络时代自然语言处理研究最重要的语言模型。
六、生成式预训练模型的强大展示: ChatGPT
GPT 的训练参数越来越多。 2018 年 6 月开发的 GPT 有 1.17 亿个参数。 2019 年 2 月开发的 GPT-2 有 15 亿个参数,实现了无监督的多任务学习,具有一定的自我纠偏能力。GPT-2 开始训练的数据取 自著名社交站点 Reddit 上的文章,累计有 800 万 篇。 2020 年 5 月, GPT-3 启动,有 1750 亿个参数, 开始了大规模的机器学习,把能获取到的人类书籍、学术论文、新闻、高质量的各种信息作为学习 内容,并形成了“基于人类反馈的强化学习方案”(RLHF)。后来,又在此基础上开发出 ChatGPT。 ChatGPT 可以通过使用大量的训练数据来模拟人的语言行为,生成人类可以理解的文本,并根据上下 文语境,给出恰当的回答,甚至还能做句法分析和语义分析,帮助用户调试计算机程序,写计算机程 序的代码,达到了很强的自然语言生成能力。
2022 年 11 月 30 日, ChatGPT 开放公众测试,真正实现了完全自主的“人工智能内容生成”(AIGC), 包括文本生成、代码生成、视频生成、文本问答、图像生成、论文写作、影视创作、科学实验设计等。
现在的 ChatGPT 是由效果比 GPT-3 更强大的 GPT-3.5 系列模型提供支持的,这些模型使用微软 Azure AI 超级计算基础设施上的文本和代码数据进行训练。据说, GPT-4 的参数将高达 100 万亿。这 是真正的大语言模型。
交互式是 ChatGPT 的一大优点,用户可以自如地与 ChatGPT 对话,自然而且流畅。ChatGPT 的回 答是连续的、稳定的、一致的,用户与 ChatGPT 对话,就像是与朋友聊天。
ChatGPT 也承认它还存在一些不足。最近《时代周刊》对 ChatGPT 做了一个专访。聊天记录如下: 记者:我应该相信你刚才说的一切都是真的吗?
ChatGPT :作为一个大型语言模型,我被设计成对各种各样的输入产生类似人类的反应。我 尽我所能提供准确和有用的信息,但我不是一个完美的知识来源,可能不总是能够提供完整或正 确的答案。此外,我不能浏览互联网或访问任何外部的信息,所以我的反应仅限于我所得到的训 练数据和算法。这意味着我的回答中可能有一些错误或不准确的地方,你不应该把我所说的都当 成真实和准确的。在做任何重要决定或采取任何行动之前,运用自己的判断和常识核实多方信 息,才是重要的。
由于 ChatGPT 不能像搜索引擎那样提供实时的信息,有时甚至会提供不符合事实的错误答案,或 者一本正经地胡说八道,或者说一些永远正确的废话。这是因为 ChatGPT 实际上只是一个大规模的语 言模型,只能在大规模数据的基础上对人类的语言行为进行模仿,并没有真正理解聊天的内容。实际 上, ChatGPT 尽管能够针对人类的输入产生类似于人类的反应,然而,它并不知道它知道什么,也不 知道它不知道什么,并不能真正地理解自然语言。
ChatGPT 的成功,归根结底是人类智慧的胜利,因为 ChatGPT 是由人类研制出来的,它的智慧是人类赋予的。ChatGPT 的出现,使得人工智能由感知智能进入了认知智能,而且改变了在此之前的简 单的人机关系,并将带来一个人机合作的新时代。
七、结 语
虽然 ChatGPT 具有优异的对话性能,但我们仍要清醒地认识到,人类对于自然语言的理解,除了 依靠语言内部各种关系的知识之外, 还需要依靠外部物理世界、外部精神世界和外部社会历史世界等 背景知识。自然语言文本中的每一个符号、每一个合乎规则结构的符号串,在人脑中都与外部的客观 世界有着千丝万缕的联系。这些复杂联系不仅以语言数据中的符号形式表现出来,还具有更深入的心 理感情表征以及社会文化背景。然而, ChatGPT 使用生成式预训练模型从大规模语言数据中获取的大 量参数,基本上都是基于自然语言数据的参数, 还没有这些语言数据与语言外部的客观世界的千丝万 缕联系的参数。因此, ChatGPT 只是处理自然语言本身的数据,并不能处理丰富多彩的语言外信息。 所以,我们认为, ChatGPT 尽管已经取得了很大进步,已经具有强大的处理人类语言数据的能力,但 是它处理外在世界的普通常识以及社会历史背景的能力还十分有限。从本质上说, ChatGPT 具备的智 能还不是完善的人类智能,只是初级阶段的人类智能,而语言是人类的高级智能活动,不仅涉及语言 内部的结构, 还涉及语言外部的日常生活知识、科学技术知识、历史知识、社会知识、文化背景知 识、人们的情感愿望、人们的心理状态等丰富多彩的因素。自然语言是极为复杂的,要进一步提高自 然语言处理的水平,让计算机真正地理解自然语言,仍然还是一个极为困难的任务。我们还要继续努 力,用新技术来探索自然语言的奥秘(冯志伟,张灯柯 2022)。
与此同时,纵观从图灵测试到 ChatGPT 人工智能中人机对话系统的历程,其背后数据资源、技术 迭代和科学范式都发生了巨大的变化。人工智能借由人机对话深入地介入了语言生活。这一发展过程 中,语言学和语言学家在不同时期有所介入,但总体而言并不多。随着人机对话性能的飞速提升,语 言学和语言学家需要正视冲击,并进行反思。语言中知识的表示和挖掘方法,语言使用中的伦理,都 是当今人机共生语言生活中亟待研究的问题(饶高琦 2022)。面对新时代的要求,语言学家应当与时 俱进,进行更新知识的再学习,成为适应数智时代需要的语言学家。